Jeremy Allison Column Archives
A Tale of Two Standards
as Published in Open Sources 2.0
“It was the best of protocols, it was the worst of protocols, it
was the age of monopoly, it was the age of Free Software, it was the
epoch of openness, it was the epoch of proprietary lock-in, it was the
season of GNU, it was the season of Microsoft, it was the spring of
Linux, it was the winter of Windows….”
Samba is commonly used as the ‘glue’ between the separate worlds
of Unix and Windows, and because of that Samba developers have to intimately
understand the design and implementation decisions made in both systems.
It is no surprise that Samba is considered one of the most difficult
Free Software projects to understand and to join, only outclassed in
complexity by the voodoo black art of Linux kernel development. It really
isn’t that hard, however, once you look at the different standards implemented
in the two systems, (although some of the more decisions in Windows
can cause raised eyebrows).
In developing Samba we’re creating a bridge between the most popular
standards currently deployed in the computing world, the Unix/Linux
standard of POSIX and the Microsoft developed defacto standard of Win32.
In this article I want to examine these two standards from an application
programmer’s perspective. In doing so I thought it might be instructive
to look at the reasons why each of them exist, what the intention creating
the particular standard might have been, and how well they have stood
the test of time and the needs of programmers. A historical perspective
is very important as we look to the future and decide what standards
should we encourage governments and business to support and what effect
this will have on the software landscape in the early 21st Century.
“Standards; (noun) A flag, banner, or ensign, especially: An emblem
or flag of an army, raised on a pole to indicate the rallying point
in battle.”
The POSIX Standard
POSIX was named (like so many things in the Unix software world)
by Richard Stallman. It stands for “Portable Operating System Interface”
– X ; meaning a portable definition of a Unix like operating system
API. The reason for the existence of the POSIX standard is interesting,
and lies in the history of the Unix family of operating systems.
As is commonly known, Unix was first created at AT&T Bell labs
by Ken Thompson and Dennis Richie in 1969. Not originally designed for
commercialization, the source code was shipped to universities around
the world, most notably Berkeley in California. One of the world’s first
truly portable operating systems, Unix soon splintered into many different
versions as people modified the source code to meet their own requirements.
Once companies like Sun Microsystems and the original, pre-litigious
SCO (Santa Cruz Organization) began to commercialize Unix, the original
Unix system call application programming interface (API) remained the
core of the Unix system, but each company added proprietary extensions
to differentiate their own version of Unix. Thus began the first of
“the Unix wars” (I’m a veteran, but don’t get disability benefits
for the scars they caused). For independent software vendors (ISV’s)
such proprietary variants were a nightmare. You couldn’t assume that
code that ran correctly on one Unix would even compile on another.
During the late 1980’s, in an attempt to create a common API for
all Unix systems to fix this problem the POSIX set of standards was
born. Due to the fact that no one trusted any of the Unix vendors, the
Institute of Electrical and Electronic Engineers (IEEE) shepherded the
standards process and created the 1003 series of standards, known as
POSIX. The POSIX standards cover much more than the operating system
API’s, going into detail on system commands, shell scripting and many
other parts of what it means to be a Unix system. I’m only going to
discuss the programming API standard part of POSIX here, because as
a programmer that’s really the only part of it I care about on a day-to-day
basis.
Few people have actually seen an official POSIX standard document,
as the IEEE charges money for copies. Back before the Web became really
popular I bought one , just to take a look at what the real thing looked
like. It wasn’t cheap (a few hundred dollars as I recall). Amusingly
enough I don’t think Linus Torvalds ever read one or referred to it
when originally creating Linux; he used other vendors’ references to
it and manual page descriptions of what POSIX calls were supposed to
do.
Reading the paper POSIX standard however is very interesting. It
reads like a legal document; every line of every section is numbered
so it can be referred to in other parts of the text. It’s detailed.
Really detailed. The reason for such detail is that it was designed
to be a complete specification of how a Unix system has to behave when
called from an application program. The secret is that it was meant
to allow someone reading the specification to completely re-implement
their own version of a Unix operating system starting from scratch,
with nothing more than the POSIX spec. The goal is that if someone writes
an application that conforms to the POSIX specification, then the resulting
application can be compiled with no changes on any system that is POSIX
compliant. There is even a POSIX conformance suite, which allows a system
passing the tests to be officially branded a POSIX-compliant system.
This was created to reduce costs in government and business procurement
procedures. The idea was you specified “POSIX compliant” in your
software purchasing requests, and the cheapest system that had the branding
could be selected and it would satisfy the system requirement.
This ended up being less useful than it sounds, given that Microsoft
Windows NT has been branded POSIX-compliant and generic Linux has not.
Sounds wonderful, right? Unfortunately reality intruded its ugly
head somewhere along the way. Vendors didn’t want to give up their proprietary
advantages and so all of them pushed to get their particular implementation
of a feature into POSIX. As all vendors don’t have implementations of
all parts of the standard this means that many of the features in POSIX
are optional, usually just the one you need for your particular application.
How can you tell if a particular implementation of POSIX has the feature
you need? If you’re lucky, you can test for it at compile time.
The GNU project suffered from these “optional features” more
than most proprietary software vendors, as their software is intended
to be portable across as systems as possible. In order to make their
software portable across all the weird and wonderful POSIX variants
the wonderful suite of programs known as GNU autoconf were created.
The GNU autoconf system allows you to test to see if a feature exists,
or works correctly, before even compiling the code; thus allowing an
application programmer to degrade missing functionality gracefully (ie.
not failing at runtime).
Unfortunately not all features can be tested this way, as sometimes
a standard can give too much flexibility, thus causing massive runtime
headaches. One of the most instructive examples is in the pathconf()
call. The function prototype for pathconf() looks like this :
long pathconf(char *path, int name);
Here, “char *path” is a pathname on the system and “int name”
is a defined constant giving a configuration option you want to query.
The ones causing problems are the :
- _PC_NAME_MAX
- _PC_PATH_MAX
constants. _PC_NAME_MAX queries for the maximum number of characters
that can be used in a filename within a particular directory (specified
by “char *path”) on the system. _PC_PATH_MAX queries for the maximum
number of characters that can be used in a relative path from the particular
directory. On the surface there seems nothing wrong with this, until
you consider how Unix file systems are structured and put together.
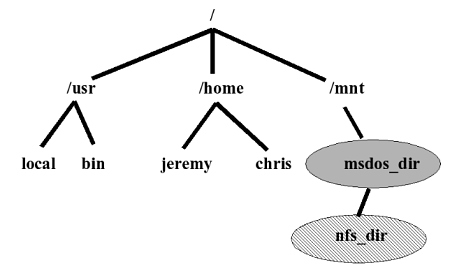
A typical Unix file system looks like this :
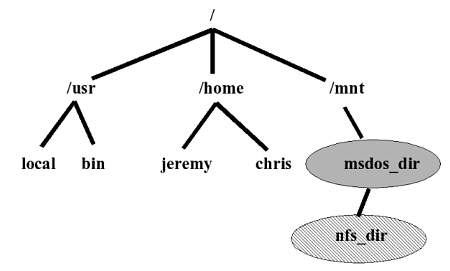
Any of the directory nodes such as /usr/bin or /mnt could be a different
file system type, not the standard Unix file system (maybe even network
mounted). In the diagram, the “/mnt/msdos_dir” path has been mounted
from a partition containing an old MS-DOS style FAT file system type.
The maximum directory entry length on such a system is the old DOS 8.3
eleven character name. But below the Windows directory could be mounted
a different file system type with yet other differing maximum name restrictions
than 8.3, maybe an NFS mount from a different machine, for example on
the path : “/mnt/msdos_dir/nfs_dir“. Now the pathconf() can accommodate
these restrictions and tell your application about it, if you remember
to call it on every single possible path and path component your application
might use ! Hands up all application programmers who actually do this……
Yes, I thought so (you at the back, put your hand down. I know how you
do things in the USA “Star Wars” missile defense program but no
one programs in ADA anymore, plus your tests never work, OK ?). This
is an example of something that looks good on paper but in practical
terms almost no one would use in an actual application. I know we don’t
in Samba, not even in the “re-written from scratch with correctness
in mind” Samba4 implementation.
Now let’s look at an example of where POSIX gets it spectacularly
wrong, and why it happened.
First Implementation Past the Post
Any application program dealing with multiple access to files has
to deal with file locking. File locking has several potential strategies,
ranging from the “lock this file for my exclusive use” method, to
the “lock these 4 bytes at offset 23 as I’m going to be reading from
them soon” level of granularity. POSIX does implement this kind of
functionality via the fcntl() call, a sort of “jack of all trades”
for manipulating files (hence “fcntl -> file control”). It’s
not important exactly how to program this call, suffice it to say that
a code fragment to set up a byte range lock as described above looks
something like :
int fd = open("/path/to/file", O_RDWR);
…. set up “struct flock” structure to describe the kind of
byte range lock we need…
int ret = fcntl(fd, F_SETLKW, &flock_struct);
and if ret is zero, we got the lock. Looks simple, right? The byte
range lock we got on the region of the file is advisory. This means
that other processes can ignore it and are not restricted in reading
or writing the byte range covered by the region (that’s a difference
from the Win32 way of doing things, in which locks are mandatory; if
a lock is in place on a region no other process can write to that region
even if it doesn’t test for locks). An existing lock can be detected
by another process doing its own fcntl() call asking to lock its own
region of interest. Another useful feature is that once the file descriptor
open on the file (int fd in the example above) is closed then the lock
is silently removed. This is perfectly acceptable and a rational way
of specifying a file locking primitive, just what you’d want.
However, modern Unix processes are not single threaded any more,
they commonly consist of a collection of separate threads of execution,
separately scheduled by the kernel. Because the lock primitive has a
per-process scope, this means that if separate threads in the same process
ask for a lock over the same area it won’t conflict. In addition, because
the number of lock requests by a single process over the same region
is not recorded (according to the spec) then you can lock the region
ten times, but you only need to unlock it once. This is sometimes what
you want, but not always: consider a library routine that needs to access
a region of a file but doesn’t know if the calling processes has the
file open. Even if an open file descriptor is passed into the library,
the library code can’t take any locks, it can never know if it is safe
to unlock again without race conditions.
This is an example of a POSIX interface not being future-proofed
against modern techniques such as threading. A simple amendment to the
original primitive allowing a user-defined “locking context” (like
a process id) to be entered in the struct flock structure used to define
the lock would have fixed this problem, along with extra flags allowing
the number of locks per context to be recorded if needed.
But it gets worse. Consider the following code:
int second_fd;
int ret;
struct flock lock;
int fd = open("/path/to/file", O_RDWR);
/* Set up the "struct flock" structure to describe the
kind of byte range lock we need. */
lock.l_type = F_WRLCK;
lock.l_whence = SEEK_SET;
lock.l_start = 0;
lock.l_len = 4;
lock.l_pid = getpid();
ret = fcntl(fd, F_SETLKW, &lock);
/* Assume we got the lock above (ie. ret == 0). */
/* Get a second file descriptor open on
the original file. Assume this succeeds. */
second_fd = dup(fd);
/* Now immediately close it again. */
ret = close(second_fd);
What do you think the effect of this code on the lock created on
the first file descriptor should be (so long as the close() call returns
zero) ? If you answered “it should be silently removed when the second
file descriptor was closed”, congratulations, you have the same warped
mind as the people who implemented the POSIX spec. Yes, that’s correct.
Any successful close() call on any file descriptor referencing a file
with locks will drop all the locks on that file, even if they were obtained
on another, still open, file descriptor.
Let me be clear to everyone: this behavior is never what you would
want. Even experienced programmers are surprised by this behavior, because
it makes no sense. Even after I’ve described this to Linux kernel hackers
their response has been one of stunned silence, followed by a “but
why would it do that”?
In order to discover if this functionality was actually correctly
used by any application program or anything really depended on it, Andrew
Tridgell, the original author of Samba once hacked the kernel on his
Linux laptop to write a kernel debug message if ever this condition
occurred. After a week of continuous use he found one message logged.
When he investigated it turned out be be a bug in the “exportfs”
NFS file exporting command, where a library routine was opening and
closing the /etc/exports file that had been opened and locked by the
main exportfs code. Obviously the authors didn’t expect it to do that
either.
The reason is historical and reflects a flaw in the POSIX standards
process, in my opinion, one that hopefully won’t be repeated in the
future. I finally tracked down why this insane behavior was standardized
by the POSIX committee by talking to long-time BSD hacker and POSIX
standards committee member Kirk McKusick (he of the BSD daemon artwork).
As he recalls, AT&T brought the current behavior to the standards
committee as a proposal for byte-range locking, as this was how their
current code implementation worked. The committee asked other ISVs if
this was how locking should be done. The ISVs who cared about byte range
locking were the large database vendors such as Oracle, Sybase and Informix
(at the time). All of these companies did their own byte range locking
within their own applications, none of them depended on or needed the
underlying operating system to provide locking services for them. So
their unanimous answer was “we don’t care”. In the absence of any
strong negative feedback on a proposal, the committee added it “as-is”,
and took as the desired behavior the specifics of the first implementation,
the brain-dead one from AT&T.
The “first implementation past the post” style of standardization
has saddled POSIX systems with one of the most broken locking implementations
in computing history. My current hope is that eventually Linux can provide
a sane superset of this functionality that may then be adopted by other
Unixes and eventually find its way back into POSIX.
OK, having dumped on POSIX enough, let’s look at one of the things
that POSIX really got right, and is an example to follow in the future.
Future Proofing
One of the great successes of POSIX is the ease in which it has adapted
to the change from 32-bit to 64-bit computing. Many POSIX applications
were able to move to a 64-bit environment with very little or no change,
and the reason for that is abstract types.
In contrast to the Win32 API (which even has a bit-size dependency
in its very name), all of the POSIX interfaces are defined in terms
of abstract data types. A file size in POSIX isn’t described as a “32
bit integer” or even as a C language type of “unsigned int“, but
as the type of “off_t“. What is “off_t“? The answer depends
completely on the system implementation. On small or older systems it
is usually defined as a signed 32 bit integer (it’s used as a seek position
so it can have a negative value), on newer systems (Linux for example)
it’s defined as a signed 64-bit integer. So long as applications are
careful to only cast integer types to the correct “off_t” type and
use these for file size manipulation then the same application will
work on both small and large POSIX systems.
This wasn’t done all at once, as most commercial Unix vendors have
to provide binary compatibility to older applications running on newer
systems, so POSIX had to cope with both 32-bit file sized applications
running alongside newer 64-bit capable applications on the new 64-bit
systems. The way to make this work was decided at the Large File Support
working group, which finished its work during the mid 1990’s.
The transition to 64-bits was seen as a three stage process. Stage
one was the original old 32-bit applications; stage two was seen as
a transitional stage, where new versions of the POSIX interfaces were
introduced to allow newer applications to explicitly select 64-bit sizes,
and finally; stage three where all the original POSIX interfaces default
to being 64 bit clean.
As is usual in POSIX, the selection of what features to support was
made available using compile-time macro definitions that could be selected
by the application writer. The macros used were :
_LARGEFILE_SOURCE
If defined a few extra functions were made available to applications
to fix the problems in some older interfaces, but the default file access
was still 32-bit. This corresponds to stage one described above.
_LARGEFILE64_SOURCE
If this is defined then a whole new set of interfaces are available
to POSIX applications that can be explicitly selected for 64-bit file
access. These interfaces explicitly allow 64-bit file access and have
’64’ coded into their names. So open() becomes open64(),
lseek() becomes
lseek64(), and a new abstract data type called off64_t is
created and used instead of the off_t file size data type in such structures as
struct stat64. This corresponds to stage two.
_FILE_OFFSET_BITS
This represents stage three, and this macro can be either undefined
or set to the values 32 or 64. If undefined or set to 32 it corresponds
to stage one (_LARGEFILE_SOURCE). If set to 64 all the original interfaces
such as open() and lseek() are transparently mapped
to the 64-bit clean
interfaces. This is the end stage of porting to 64-bits, where the underlying
system is inherently 64-bit, and nothing special need be done to make
an application 64-bit aware. On a native 64-bit system that has no older
32-bit binary support this becomes the default.
As you can see, if a 32-bit POSIX application had no dependencies
on file size embedded in it, then simply adding the compile time flag
“-D_FILE_OFFSET_BITS=64” would allow a transparent port to a 64-bit
system. There are few such applications though, and Samba was not one
of them. We had to go through the stage two pain of using 64-bit interfaces
explicitly (which we did around 1998) before we could track down all
the bugs associated with moving to 64-bits. But we didn’t have to re-write
completely, and that I consider a success of the underlying standard.
This is an example of how the POSIX standard was farsighted enough
to define some interfaces that were so portable and clean that they
could survive a transition of underlying native CPU word length. Few
other standards can make that claim.
Wither POSIX ?
The POSIX standard has not stayed static; it has managed to evolve
(although some would argue too slowly) over time. A major step forward
was the establishment of the “Single Unix Specification” (SUS) which
is a superset of POSIX developed in 1998 and adopted by all the major
Unix vendors, shepherded by the Unix standards body “the Open Group”.
It was a great leap forward when this specification was finally made
available for free on the Web from the OpenGroup Web site at http://www.unix.org.
It certainly saved me from having to hunt down cheap POSIX specifications
in second hand bookshops in Mountain View, California.
The expanded SUS now covers such things as real-time programming,
concurrent programming via the POSIX thread (pthread) interfaces, internationalization
and localization, but unfortunately not file Access Control Lists (ACLs).
Sadly that specification was never fully agreed on, and so has never
made it into the official documents. Interestingly enough the SUS doesn’t
cover such things as the graphical user interface (GUI’s) elements,
as the history of Unix as primarily a server operating system meant
that GUI’s were never given the importance needed for Unix to become
a desktop system.
Looking at what happened with ACLs is instructive in considering
the future of POSIX and the SUS. Because ACLs were sorely needed in
real-world environments the individual Unix vendors such as SGI, Sun,
HP and IBM added them to their own Unix variants. But without a true
standards document they fell into their old evil ways and added them
with different specifications. Then along came Linux….
Linux changed everything. In many ways, the old joke is true that
Linux is the Unix defragmentation tool inspired by novice system administrators
coming to Unix from the Windows platform for the first time and asking
“where is the system defragmentation tool?”, the concept of a file
system designed well enough not to need one being outside their experience.
As Linux became more popular programs originally written for other Unixes
were first ported to it, then after a while were written for it and
then ported to other platforms. This happened to Samba, where Sun’s
SunOS on SPARC system was at first our primary user platform but after
five years or so rapidly migrated to Linux on Intel x86 systems. We
now develop almost exclusively on Linux, and from there port to other
Unix systems.
What this means is the Linux interfaces are starting to take over
as the most important standards for Unix-like systems to follow, in
some ways supplanting POSIX and the SUS. The ACL implementation for
Linux was added into the system at first via a patch by Andreas Grünbacher,
held externally to the main kernel tree. Finally it was adopted by the
main Linux vendors SuSE (now Novell) and Red Hat and has become part
of the official kernel. Other free Unix systems such as FreeBSD quickly
followed with their own implementation of the last draft of the POSIX
ACL specification, and now there are desktop GUI and other application
programs that use the Linux ACL interfaces. As this code is ported to
other systems the pressure is on them to conform to the Linux API’s,
not to any standards document. Sun have announced that their Solaris
10 on Intel release will run Linux applications “better than Linux”
and will be fully compatible at the system call level with Linux applications.
This means they must have mapped the Linux ACL interface onto the Solaris
one. Is that a good thing ?
In a world where Linux is rapidly becoming the dominant version of
Unix, does POSIX still have relevance, or should we just assume Linux
is the new POSIX ?
The Win32 (Windows) Standard
Win32 was named for an expansion of the older Microsoft Windows interface,
renamed the Win16 interface once Microsoft was shipping credible 32-bit
systems. I have a confession to make; in my career I completely ignored
the original 16-bit Windows on MS-DOS. At that time I was already working
on sane 32-bit systems (68000 based) and having to deal with the original
insane 8086 segmented architecture was too painful to contemplate. Win32
was Microsoft’s attempt to move the older architecture beyond the limitations
of MS-DOS and into something that could compete with Unix systems, and
to a large extent they succeeded spectacularly.
The original 16-bit Windows API added a common GUI on top of MS-DOS,
and also abstracted out the lower level MS-DOS interfaces so application
code had a much cleaner “C” interface to operating system services
(not that MS-DOS provided many of those). The Win32 Windows API was
actually the “application” level API (not the system call level;
I’ll discuss that in a moment) for a completely new operating system
that would soon be known as Windows NT (“New Technology”). This
new system was designed and implemented by Dave Cutler, the architect
of Digital Equipment Corporation’s VMS system, long a competitor to
Unix. It does share some similarities with VMS. The interface choice
for applications was very interesting, sitting on top of a system call
interface that looks like this :
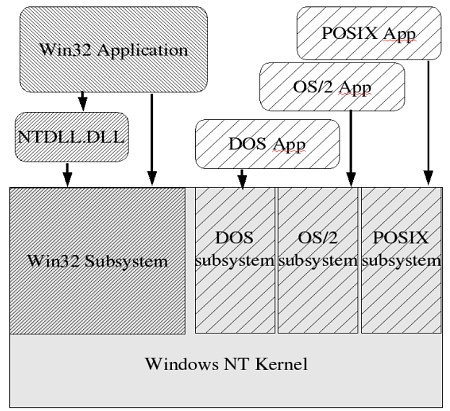
The original idea behind the Windows NT kernel was that it could
host several different “subsystem” system call interfaces, providing
completely different application behavior from the same underlying kernel.
Thus it was meant to be a completely customizable operating system,
providing different kernel “personalities” any ISV might require.
The DOS subsystem and the (not shown) 16-bit Windows subsystem were
essential as they provided backwards compatibility for applications
running on MS-DOS and 16-bit Windows; the new operating system would
have gathered little acceptance had it not been able to run all the
old MS-DOS and Windows applications. The OS/2 subsystem was designed
to allow users of text mode OS/2 applications (which was at one time
a Microsoft product) to port them to Windows NT.
The two interesting subsystems are the original POSIX subsystem and
the new Win32 subsystem. The POSIX subsystem was added as the POSIX
standard had become very prevalent in procurement contracts. Many of
these valuable contracts were only available to systems that passed
the POSIX conformance tests. So Microsoft added a minimal POSIX subsystem
into the new Windows NT operating system. This original subsystem was,
I think it’s fair to say, deliberately crippled to make it not useful
for any real-world applications. Applications using it had no network
access and no GUI access, so although a POSIX compliant system might
be required in a procurement contract, there usually was no requirement
that the applications running on that system had to also be POSIX compliant.
This allowed new applications using the Microsoft preferred Win32 subsystem
to be used instead. All might not have been lost if Microsoft had documented
the internal subsystem interface, allowing third party ISVs to create
their own Windows NT kernel subsystems, but Microsoft kept this valuable
asset purely to themselves (there was one exception to this which I’ll
discuss below).
So let’s examine the Win32 standard API, the interface designed to
run on top of the Win32 kernel subsystem. It would be logical to assume
that, like the POSIX system calls, the calls defined in the Win32 API
would closely map to kernel level Win32 subsystem system calls. But
that would be incorrect. It turns out that, when released, the Win32
subsystem system call interface was completely undocumented. The calls
made from the application level Win32 API were translated, via various
shared libraries (“DLLs” in Windows parlance) mainly the NTDLL.DLL
library, into the real Win32 subsystem system calls.
Why do this, you might ask? Well the above board reason is that it
allows Microsoft to tune and modify the system call layer at will, improving
performance and adding features without being forced to provide backwards
compatibility application binary interfaces (or “ABI’s” for short).
The more nefarious reasoning is that it allows Microsoft applications
to cheat, and call directly into the undocumented Win32 subsystem system
call interface to provide services that competing applications cannot.
Several Microsoft applications were subsequently discovered to be doing
just that of course. One must always remember that Microsoft is not
just an operating systems vendor, but also the primary vendor of applications
that run on its own platforms. These days this is less of a problem,
as there are several books that document this system call layer, and
there are several applications that allow snooping on any Windows NT
kernel calls being made by applications, allowing any changes in this
layer to be quickly discovered and published. But it left a nasty taste
in the mouths of many early Windows NT developers (myself included).
The original Win32 application interface was on the surface very
well documented, and cheaply available in paper form (five books at
only twenty dollars each; a bargain compared to a POSIX specification).
Like most things in Windows, on the surface it looks great. It covers
much more than POSIX tries to standardize, and so offers flexible interfaces
for manipulating the GUI, graphics, sound, pen computing, as well as
all the standard system services such as file I/O, file locking, threading,
and security. Then you start to program with it. If you’re used to the
POSIX specifications you almost immediately notice something is different.
The details are missing. It’s fuzzy on the details. You notice it the
first time you call an API at runtime and it returns an error that’s
not listed anywhere in the API documentation. “That’s funny….?”
you think. With POSIX, all possible errors are listed in the return
codes section of the API call. In Win32, the errors are a “rough guide”.
The lack of detail is one of the reasons that the Wine project finds
it difficult to create a working implementation of the Win32 API on
Linux. How do you know when it’s done ? Remember that Linus with some
help was able to create a decent POSIX implementation within a few years.
The poor Wine developers have been laboring at this for twelve years
and it’s still not finished. There’s always one more wrinkle, one more
undocumented behavior that some critical application depends on. Reminds
me of Samba somehow, and for very similar reasons.
It’s not entirely Microsoft’s fault. They haven’t documented their
API because they haven’t needed to. POSIX was documented to this detail
due to need: the need of the developers creating implementations of
the standard. Microsoft know that whatever they make the API do in the
next service pack, that’s still the Win32 standard. “Where ever you
go, there you are”, so to speak.
However, the Win32 design does some things very well; security, for
instance. Security isn’t the number one thing people think of when considering
Windows, but in the Win32 API security is a very great concern. In Win32,
every object can be secured, and a property called a “Security Descriptor”
which contains an access control list (ACL) can be attached to it. This
means objects like processes, files, directories, even Windows can have
ACLs attached. This is much cleaner than POSIX, where only objects in
the file system can have ACLs attached to them.
So let’s look at a Win32 ACL. Like in POSIX, all users and groups
are identified by an unique identifier. On POSIX it’s a uid_t type for
users, and a gid_t type for groups. In Win32, both are of type SID or
security identifier. A process or thread in Win32 has a token attached
to it which lists the primary SID of the process owner and a list of
secondary group SID entries this user belongs to. Like in POSIX, this
is attached to a process at creation time and the owner can’t modify
it to give themselves more privileges. A Win32 ACL consists of a list
of SID entries with an attached bit mask identifying the operations
this SID entry allows or denies. Sounds reasonable, right? But the devil
is in the details.
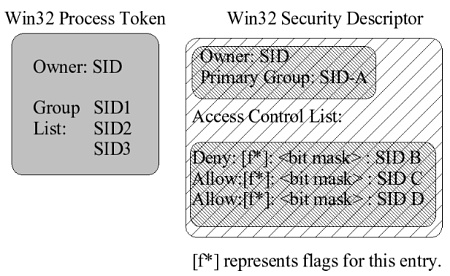
Each SID entry in an ACL can be an allow entry, or a deny entry.
The order of them is important. Re-order a list of entries and swap
an deny entry with an allow entry and the meaning of the ACL can completely
change. POSIX ACLs don’t have that problem because the evaluation algorithm
defines the order in which entries are examined. In addition, the flags
defining the entry (marked as [f*] above) control if an entry is inherited
when the ACL is attached to a “container object” (such as a directory
in the file system) and may also affect other attributes of this particular
entry.
The bit mask enumerates the permissions that this entry is allowing
or denying. But the permissions are (naturally) different depending
on what object the ACL is attached to. Let’s look at the kind of permissions
available for a file object :
DELETE : Delete the object.
READ_CONTROL : Read the ACL on an object.
WRITE_DAC : Write the ACL on an object.
FILE_READ_DATA : Read from the file.
FILE_READ_ATTRIBUTES : Read file meta-data.
FILE_READ_EA : Read extended attributes
(if the file has any)
FILE_WRITE_DATA : Write to the file
FILE_WRITE_EA : Write extended attributes
(if the file has any)
FILE_EXECUTE : Open for execute
(why do we need the .EXE tag then?)
SYNCHRONIZE : A permission related to an open
file handle, not the file.
And this is one of the more simple kinds of permission bearing object
in Win32.
If the Win32 API treats security so seriously, why does Windows fail
most security tests in the real world? The answer is that most applications
ignore this wonderful, flexible security mechanism; because it’s just
too hard to use. Just like the problem with the POSIX pathconf() call.
No one can use it correctly; your application would degenerate into
a mess. It doesn’t help that Microsoft, having realized the APIs controlling
security were too hard to use, has been adding functions to simplify
this mess, sometimes adding new APIs with a new service pack. In addition,
they’ve been extending the underlying semantics of the security mechanism,
adding new flags and new behaviors as they moved into the “Active
Directory” world.
Try taking a look at the “file security dialog” in Windows 2000.
It’s incomprehensible. No one, especially a system administrator, can
keep track of this level of detail across their files. Everyone just
sets one default ACL on the root of a directory hierarchy and hopes
for the best. Most administrators usually want to do two simple things
with an ACL. Allow group “X” but not user “Y”, and allow group
“X” and also user “Z”. This is just about comprehensible with
POSIX ACLs, although they’re near the limit of the complexity people
can deal with. The Win32 security system is orders of magnitude more
complex than that; it’s hopelessly over designed. Computer scientists
love it, as it’s possible to do elegant little proofs of how secure
it is, but in the real world it’s simply too much to deal with effectively.
A great idea, adding ACLs to every system object, but a real shame about
the execution.
Just to spread the blame around, the networking “experts” who
designed the latest version of Sun’s network file system, NFS version
4, fell in love with this security mechanism and decided it would be
a great idea to add it into the NFSv4 specification. They probably thought
it would make interoperability with Windows easier. Of course they didn’t
notice that Microsoft had been busily extending the security mechanism
as Windows has developed, so they standardized on an old version of
the Windows ACL mechanism, as Microsoft documented it (not as it actually
works). So now the Unix world has to deal with this mess, or rather,
a new network file system with an ACL model that is almost but not quite
compatible with Windows ACLs, and completely alien to anything currently
found on Unix. I sometimes feel Unix programmers are their own worst
enemies.
The Tar Pit: Backwards Compatibility
Now, as an example of where Win32 got things spectacularly wrong,
I want to look at a horror from the past, that unfortunately got added
into the Win32 interfaces due to the MS-DOS heritage. My pet hate with
Win32 is the idea of “share modes” on open files. In my opinion,
this one single legacy design decision has probably done more to hold
back the development of cluster aware network file systems on Win32
systems than anything else.
Under POSIX, an open() call is very simple. It takes a pathname to
open, the way in which you want to access or create the file (read,
write or both with various create types) and a permission mask that
gets applied to files you do create. Under Win32, the equivalent call
CreateFile() takes seven parameters, and the interactions between them
can be ferociously complex. The parameter that causes all the trouble
is the “ShareMode” parameter. This can take values of any of the
following constants OR’ed together :
FILE_SHARE_READ : Allow others to open for read FILE_SHARE_WRITE : Allow others to open for write FILE_SHARE_NONE : Don't allow any other opens FILE_SHARE_DELETE : Allow open for delete intent
In order to make the semantics here work this means that any Windows
kernel dealing with a file open has to know the about every other application
on the system that might have this file open. This was fine back in
the single machine MS-DOS days, when these semantics were first designed,
but is a complete disaster when dealing with a clustered file system
where a multitude of connected file servers may want to give remote
access to the same file, even if they’re only serving out the file read-only
to applications. They have to consult some kind of distributed lock
management system in order to keep these MS-DOS inherited semantics
working. While this can be done, but it complicates the job enormously
and means cluster communication on every CreateFile() and
CloseHandle()
call.
This is the bane of backwards compatibility at work. This idea of
“share modes” arbitrating what access concurrent applications can
have to a file is the cause of many troubles on a Windows system. Ever
wonder why Windows has a mechanism built in to allow an application
to schedule a file to be moved, but only after a reboot? Share modes
in action. Why are some files on a Windows server system impossible
to back up due to “Another program is currently using this file”
errors? Share modes again. There is no security permission that can
prevent a user opening a file with effectively “deny all” permissions.
If you can open the file for read access, you can get a share mode on
it by design. Consider a network shared copy of Microsoft office. Any
user must be able to open the file “WINWORD.EXE” (the binary file
containing Microsoft Word) in order to execute it. Given these semantics
any user can open the file with READ_DATA access with the “ShareMode”
parameter set to FILE_SHARE_NONE and thus block use of the file., even
over the network. Imagine on a Unix system being able to open the /etc/passwd
file with a share mode and denying all other processes access. Watch
the system slowly grind to a halt as the other processes get stuck in
this tar pit….
World Domination, Fast
Now I’ve heaped enough opprobrium on Win32, let’s give it a break
and consider something the designers really did get right, and one of
the advantages it has over POSIX. I’m talking about the early adoption
of the UNICODE standard in Win32. When Microsoft was creating Win32
one of the things they realized was that this couldn’t just be another
English-only, American and European-centric standard, it had to be able
to not only cope with, but encourage, applications written in all world
languages (never accuse Microsoft of thinking small in their domination
of the computing world).
Given that criteria, their adoption of UNICODE as the native character
set for all the system calls in Win32 was a stroke of genius. Even though
the Asian countries aren’t particularly fond of UNICODE as it merges
several character sets they consider separate into one set of code points,
UNICODE is the best way to cope with the requirements of internationalization
and localization in application development.
In order to allow older MS-DOS and Win16 applications to run, the
Win32 API is available in two different forms, selectable by a compiler
#define of -DUNICODE (it also helps if you own the compiler market for
Windows, as Microsoft does, as you can standardize tricks like this).
The older code page based applications call Win32 libraries that internally
convert any string arguments to 16-bit UNICODE and then call the real
Win32 library interface, which like the Windows NT kernel, is UNICODE
only.
In addition to this Win32 comes with a full set of library interfaces
to split out the text messages an application may need to display into
resource files so ISVs can easily have them translated for a target
market. This eases the internationalization and localization burdens
considerably for vendors.
What is more useful, but not as obvious, is that making the Win32
standard natively use UNICODE meant developers were immediately confronted
with the requirements of multilingual code development. So many applications
written in English speaking or Western European 8-bit character set
compatible countries are badly written, making the assumption that a
character will always fit within one byte. The early versions of Samba
definitely had that mistake and retro-fitting multi-byte character set
handling into old code is a real bear to get right. I know as I was
the person who first had to work on this for Samba (later I got some
much needed help from Andrew) so I may be a little touchy on this subject.
Whenever I did Win32 development I immediately designed with non-English
languages in mind, and wrote everything with the abstract type TCHAR
(one of the few useful abstract types in Win32), which is selectable
at compile time using the UNICODE define to be either wchar_t with UNICODE
turned on or unsigned char with UNICODE turned off. Getting yourself
in the right multi-byte character set mindset from the beginning eliminates
a whole class of bugs that you get when having to convert a quick “English
only” hacked up program into something maintainable for different
languages. POSIX has been catching up over the years with the iconv()
functionality to cope with character set conversions, and the SUN designed
gettext() interfaces for localization but Win32 had it all right from
the start.
Wither Win32 ?
As with POSIX, the Win32 standard has not stayed static over time.
Microsoft have continued to develop and extend it, and have the advantage
that anything they publish immediately becomes the “standard”, as
is the case with all single vendor defined standards.
However Microsoft is attempting to deemphasize Win32 as they move
into their new .NET environment and the new world of “managed code”.
Managed code is code running under the control of an underlying virtual
machine (called the Common Language Infrastructure, or CLI in .NET)
and can be made to prevent the direct memory access that is the normal
mode of operation of an API designed for “C” coding, such as Win32
or POSIX. Free Software is also making a push into this area too, with
the “Mono” project which implements the Microsoft C# language and
.NET managed code environment on Linux and other POSIX systems.
Even if Microsoft are as successful as they hope in pushing ISV programmers
to convert to .NET and managed code using their new C# language, the
legacy of applications developed in C using the Win32 API will linger
for decades to come. ISV programmers are an ornery lot, especially people
who have mastered the Win32 API, due to it’s less than complete documentation.
What seems to happen over the years is that experienced Win32 programmers
gain this sort of folk-knowledge about the Win32 APIs, how they really
work versus what the documentation says. I often hang out on Usenet
Windows discussion groups and it’s very interesting to watch the attitudes
of the experienced Windows programmers. They usually hate telling novices
how stuff works, it’s almost like learning it was a badge of honor,
and they don’t want to make it too easy for the neophytes. The exude
an air of “They must suffer as I did”.
As Microsoft becomes less interested in Win32 with the release of
their new “Longhorn” Windows client and the move to managed code,
is it possible for them to lose control of it? The POSIX standard is
so complete because it was designed to allow programmers reading the
standards documents to re-create a POSIX system from scratch. The Win32
standard is nowhere near as well documented as that. However there is
hope in the Wine project, which is attempting to re-create a version
of the Win32 API that is binary compatible with the Windows on Intel
x86 systems. Wine is in effect a second implementation of the Win32
system making it closer to a true vendor independent standard. Efforts
taking place at companies like CodeWeavers and Transgaming Technologies
are very promising; I just finished playing the new Windows-only game
Half Life 2 on my desktop Linux system, using the Wine technology. This
is a significant achievement for the Wine code and bodes well for the
future.
Choosing a Standard
Between two evils, I always like to take the one I’ve never tried
before. –Mae West
So what should we choose when examining what standards to support
and develop applications for? What should we recommend to business and
governments who are starting to look closely at the Open Source/Free
Software options available?
What is important is when business and governments are selecting
products based on standards, they pay attention to open standards. No
more Microsoft Word “.DOC” format standards (which suffers from
the same problem as Win32 as being single vendor controlled). No de-facto
vendor standards, no matter how convenient. They need to select standards
that are at the same level as POSIX, namely standards to the level that
other implementations can be created from the documentation. It’s simple
to tell when a standard meets that criteria because other implementations
of it exist.
The interesting thing is that both POSIX and Win32 standards are
now available on both systems. On Linux we have the POSIX standard as
native, and the Wine project provides a binary compatible layer for
compiled Win32 programs, that can run many popular Win32 applications.
Perhaps more interestingly for programmers, the Wine project also includes
a Linux shared library “winelib”, which allows Win32 applications
to be built from source code form on POSIX systems. What you end up
with is an application that looks like a native Windows application,
but can be run on non-Intel platforms; something that early versions
of Windows NT used to support, but now is restricted to x86 compatible
processors. Taking your Win32 application and porting it using winelib
is an easy way to get your feet wet in the POSIX world, although it
won’t look like a native Linux application (this may be a positive thing
it your users are used to a Windows look and feel).
If you’ve already gone the .NET and C# route, then using the Mono
project may enable your code to run on POSIX systems.
On Windows, there is now a full POSIX subsystem, supported by Microsoft
and available for free. I alluded to Microsoft’s reluctance to release
the information on how to create new subsystems for the Windows NT kernel
above, but it turns out earlier in their history they were not so careful.
A small San Francisco based company, Softway Systems, licensed the documentation
and produced a product called OpenNT (later renamed Interix), which
was a replacement for Microsoft’s originally crippled POSIX subsystem.
Unfortunately OpenNT didn’t sell very well, someone cruelly referred
to it as having “all the application availability of Linux, with the
stability of Windows”. As the company was failing, Microsoft bought
it (probably to bring the real gem of the Windows kernel subsystem interface
knowledge back in house) and used it to create their “Services for
Unix” (SFU) product. SFU contains a full POSIX environment, with a
Software development kit allowing applications to be written that have
access to networking and GUI API’s. The applications written under it
run as full peers with the native Win32 applications and users can’t
tell the difference.
Recently Microsoft made SFU available as a free download to all Windows
users. I like to think the free availability of Samba had something
to do with this, but maybe I’m flattering the Samba Team too much. As
I like to say in my talks, “if you’re not piloting Samba on Linux
in your organization, you’re paying too much for your Microsoft software”.
But what this means is if you want to write a completely portable application,
the one standard you can count on to be there and fully implemented
and supported on Windows, Linux, Solaris, Apple MacOS X, HPUX, AIX,
IRIX and all the other Unix systems out there is POSIX. So if you’ll
excuse me, I’m going to look at porting parts of Samba to Windows……
- Jeremy Allison,
- Samba Team.
- San Jose, California.
- 5th April 2005