Ollama is a tool that makes working with Large Language Models (LLMs), like Gemma 3B, much easier. Instead of having to install a mountain of dependencies and configure complex environments, Ollama simplifies the entire process.
Think of it as a personal assistant for AI that allows you to:
- Download models: Ollama lets you quickly find and download pre-trained models.
- Hassle-free testing: It eliminates the need to set up complicated development environments.
1. Install Ollama
Run the following command in your terminal:
curl -fsSL https://ollama.com/install.sh | shVisit the official Ollama website for more information or to install it on a different operating system: https://ollama.com/download
2. Install a model in Ollama
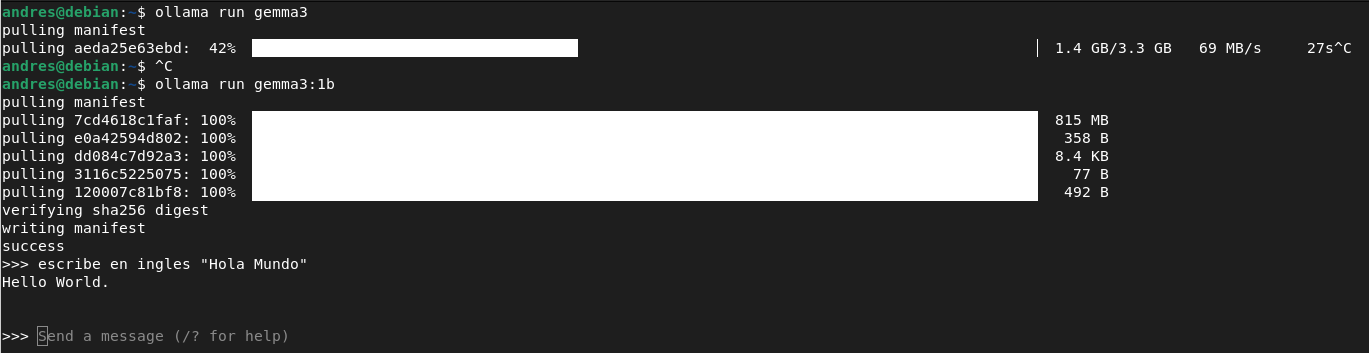
Ollama has a library where you can browse available models at https://ollama.com/search. In this example, I will install Gemma 3, a model capable of running even on a single CPU.
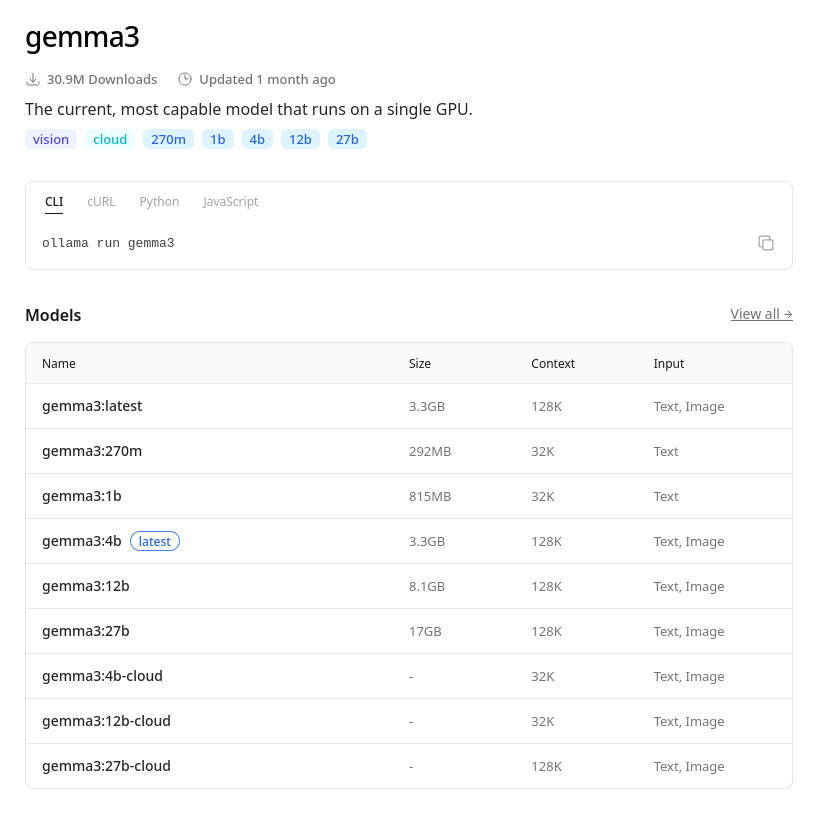
Gemma 3 model on Ollama
Execute the following command in your terminal:
ollama run gemma3:1b The text after the colon (“:”) specifies the exact version, as models can have different variations based on size, context window, supported inputs, etc.
Why use the 1B version?
Mainly for two reasons:
- Minimal RAM usage: It only requires about 1.5 GB to 2 GB of RAM.
- Instant speed: It is ideal for tasks where the response needs to be immediate.
3. Enter your prompt
Type your prompt (the question or instruction you give the model), and the Ollama terminal will display the generated text.