Smith-Waterman: an Example of the FPGA Coprocessor
Approach to Heterogeneous Computing
New techniques in genomics can provide millions of pieces of DNA from
a few tests, but transforming the mountains of raw data into meaningful
results can be a long, grueling process. Genes are usually represented
as ordered sequences of nucleotides. (Similarly, protein sequences are
strings of amino acids.) Investigators can infer a great deal about genes
and proteins from their sequence alone, and answer questions such as the
similarity of genes in different species by comparing sample sequences
to ones already classified. However, to do this, accurate methods to
determine the similarity between two sequences are critical.
Smith-Waterman is the most powerful algorithm
available for accomplishing this (Temple F. Smith and Michael S.
Waterman, “Identification of Common Molecular Subsequences”,
J. Mol. Biol., 147:195—197, 1981). But the mathematical operations
involved are difficult for commodity processors, and conventional systems
deliver extremely poor performance. By attacking the problem with the
Cray XD1—a heterogeneous system combining scalar processing with FPGA
coprocessors—investigators can accelerate Smith-Waterman and get results
up to 40 times faster than with conventional systems.
Characteristics of Smith-Waterman
The Smith-Waterman algorithm compares sample DNA or proteins against
existing databases. Because both sample and database may have errors in
the form of missing or added characters—and because a variation of a few
characters can signify major biological differences—a highly accurate
matching process is required.
Gene sequences contain four letters (G, C, A and T) for the
four nucleotides, and protein sequences contain 20 amino acid
characters. Because sequences are ordered strings, accurate comparisons
must determine whether two strings align, as well as the letters they
share. (For instance, in plain English, STOP and POTS share the same
letters but cannot satisfactorily be aligned, while POTS and POINTS can,
if a gap is created between the O and T in POTS.) Smith-Waterman uses
“dynamic programming” to find the optimal alignment. This requires
massive amounts of simple parallel computation, as well as heavy bit
manipulation, and commodity scalar processors are extremely inefficient
at these operations.
A conventional processor running Smith-Waterman requires thousands of
unique steps to compare each piece of data. The number of instructions
devoted to performing actual comparisons is a fraction of those devoted
to determining the next comparison point and the surrounding logic. In
fact, a scalar processor may devote only one instruction in 100 to
comparisons—an efficiency rate of only 1 percent.
An HPC system using an FPGA coprocessor can provide several advantages
that accelerate this algorithm. First, unlike general-purpose processors
designed to support many different types of codes, FPGAs allow for
a custom instruction set that closely mirrors the application. FPGAs
also offer huge amounts of inherent parallelism, and they can be programmed
to build thousands of compare units side by side and perform thousands
of comparisons every clock tick. In addition, hardware computation is
inherently more efficient than software at bit manipulation.
The Cray XD1 Approach
To understand fully how the Cray XD1 accelerates Smith-Waterman, it is
necessary to understand the system’s unique FPGA coprocessor architecture
(Figure 1), as well as how the application itself functions.
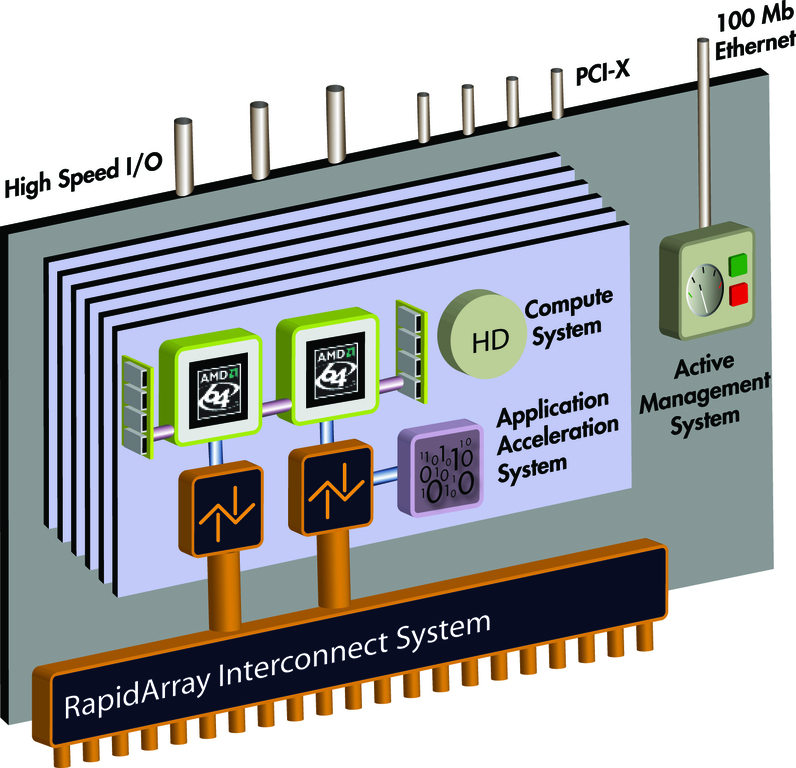
Figure 1. Cray XD1 System Architecture
Smith-Waterman formulates matches by first creating a scoring matrix
and calculating each cell according to the value of cells above and
to the left. Once this matrix is created, the algorithm calculates a
maximum score, traces back along the path that led to the score and
delivers a final alignment (Figures 2 and 3).
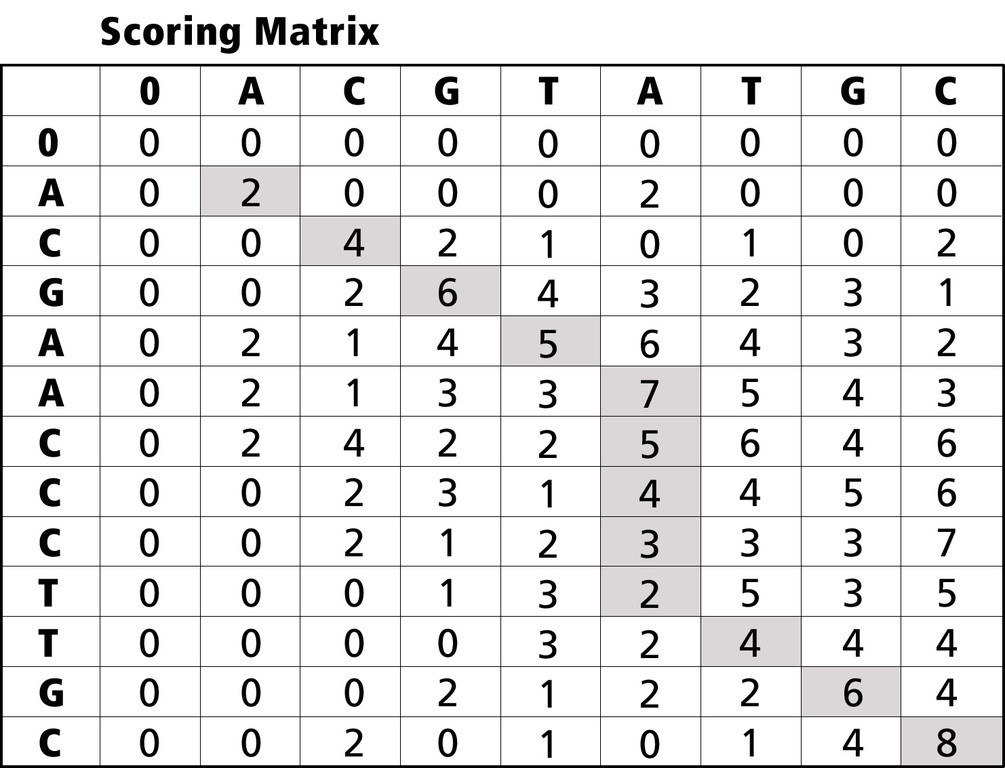

Figure 3. Smith-Waterman Formulation
To accelerate this operation, the Cray XD1 partitions the algorithm
between the system’s FPGA and Opteron processors. The system uses the
FPGA
for filling the scoring matrix (which involves parallel computation)
and sends back traceback information to the Opterons to regenerate the
matrix (a serial operation). Effectively, the system’s HPC Optimized
Linux operating system calls the FPGA solely for the kernel of the Smith-Waterman application. But the massive amount of parallelism available
with the FPGA coprocessor delivers results 25 to 40 times faster than
conventional HPC architectures. Below is an example of the
system interacting with the FPGAs:
/* Tilt the arrays by copying them to the FPGA. */
static void tilt (int fp_id, u_64 *trans_matrix, int row_len)
{
int i = 0;
u_64 status = 0;
/* Initialize the FPGA to accept a new stream of arrays. */
fpga_wrt_appif_val (fp_id, TILT_START, TILT_APP_CFG, TYPE_VAL, &e);
/* Copy the matrix to the FPGA. */
memcpy((char *) fpga_ptr, (char *) trans_matrix,
row_len*sizeof(u_64));
/* Poll to see if the FPGA has completed tilting the arays. */
while (1) {
fpga_rd_appif_val (fp_id, &status, TILT_APP_STAT, &e);
if (status & TILT_DONE) break;
}
/* When the FPGA has finished, all the transposed data will have */
/* been written by the FPGA to the transfer region of DRAM. */
/* Copy the data from the transfer region back to the array. */
// for(i=0;i
Advantages of the Cray XD1 Heterogeneous
Architecture
With the application acceleration afforded by the Cray XD1, users
can achieve much more timely results using the best algorithm
available—instead of settling for tools that deliver less-accurate
solutions more quickly. And, because the system uses the FPGA coprocessor
solely for the kernel of Smith-Waterman, it can be updated easily as the
rest of the application evolves. In addition, unlike dedicated hardware
solutions that have been available to investigators, the Cray XD1 is a
true, general-purpose HPC system. It is not limited to running a single
code, and it can be applied to other bioinformatics applications just as
easily as Smith-Waterman. In short, the Cray XD1 provides an effective,
affordable and investment-protected solution for delivering
unprecedented
performance on critical life science applications.